BUAA-OO Unit.3 Hw12 作业总结和分享
关于这篇文章
- 这篇文章只适用于北航2025OO课程,每年的指导书内容可能会有变动,具体内容请以当时课程为准。
- 这篇文章主要是记录我在OO-Unit3期间的一些记录、思考,仅作为参考,希望对读者有所帮助。
- 这篇文章仅可作为参考,笔者可能会有笔误或认识不充分的问题,希望读者包涵。
- 如果这篇文章设计学术诚信以及不可知问题,请与我取得联系,我将及时修改。
前言
课程第三单元的核心Java建模语言,学习目标为对规格化开发(以入门级 JML 规格为例)的理解与相应的代码实现。具体而言,我们需要实现课程组提供的JML,完成对简单社交关系的模拟和查询。
以下内容在未特殊声明的情况下,都基于本单元题目背景和JML。
本单元测试过程
1.1 单元测试
- 含义:单元测试是针对软件的最小可测试单元(如函数、类、方法)进行验证,确保其逻辑正确性。
- 核心目标:隔离代码单元,验证其输入输出是否符合预期,行为是否符合JML规格定义的前置条件、后置条件、不变式和副作用。
- 方法:我们可以以方法为测试单元,使用JUnit框架,根据JML的前置条件编写测试用例。在不同的状态下,通过输入不同的测试用例,判断方法的输出和类内部对象是否符合JML的要求。
- 举例:自建
Person和Tag对象,调用Person类中addTag方法测试其功能。
1.2 功能测试
- 含义:验证系统或模块的功能是否符合需求文档,它属于黑盒测试,并不关注内部实现。与单元测试不同的是,功能测试的测试范围一般较大,不会对底层方法和类进行测试。
- 核心目标:确保用户可见的功能行为正确。
- 方法:根据课程组提供的输入要求构造测试样例,模拟用户操作,查询社交网络的信息是否符合预期。
- 举例:输入一系列的
ap、ar和mr指令后查询qcs、qci等信息。
1.3 集成测试
- 含义:验证多个模块或服务协同工作的正确性,重点关注接口交互和数据流。
- 核心目标:发现模块间集成问题(如数据格式不一致、接口超时)。
- 方法:根据输入要求构造样例,对多模块协作的指令进行测试,判断多个模块协作是否预期要求。
- 举例:以
Message为例,sendMessage需要Message、Network、Person、Tag之间协作完成。我们需要对涉及到的对象和类的属性和行为进行全方面的检查。
1.4 压力测试
- 含义:评估系统在高负载或极限条件下的表现(如高并发、大数据量),确定系统瓶颈。
- 核心目标:发现性能问题(内存泄漏、响应延迟、服务崩溃)。
- 方法:通过构造点、边数量庞大的社交网络,频繁地进行增删改查,观察CPU时间和内存占用。
- 举例:可以放宽输入的要求,增加指令数量和图的大小,根据
ln指令构造大型完全图,针对特定层次(社交关系、公众号、消息等)进行特异性测试,评估性能,根据异常的时间空间占用修改代码。
1.5 回归测试
- 含义:在代码修改(如修复 Bug、新增功能)后,重新执行已有测试用例,确保原有功能未被破坏。
- 核心目标:防止“修复一个 Bug 引入另一个 Bug”。
- 方法:修改代码的Bug、优化代码性能后重新进行之前已经进行过的有效测试。
- 举例:代码修复就包含回归测试,每次重新提交代码后都会重新所有强测、互测样例进行测试,如果原来
AC的点出错就不能提交,确保了新的修复不会对原有功能进行破坏。
数据构造策略
- 对异常状态进行全覆盖:可以尝试全随机的指令生成方式,等可能生成所有指令和指令的对象,调整指令错误的概率
- 压力测试:建立完全图后对图的某个属性进行疯狂查询;特别对于延迟重建的量来说,可以采取交替的指令进行压力测试
- 代码走查:肉眼看别人的代码是否存在逻辑错误/细节错误/时间复杂度过高的问题,通过自己手搓数据进行测试。
大模型辅助规格化设计与代码实现
本次迭代作业中,我并没有使用大模型进行辅助规格化设计,我只在实现的细节方面询问了大模型。
在实验中使用大模型进行JML的,我有几点关于如何引导大模型在不同场景下如何完成复杂问题的看法:
- 明确背景和上下文。在实验中我们会强调”你是一个精通JML的工程师“之类的话明确当前的提问背景,同时我们需要给大模型输入完整的JML或者是代码,增加生成的回答的可靠性。
- 提供示例和提示。实验中我们可以给大模型喂模板,让大模型的输出尽可能的符合格式要求,提示词可以是大模型输出不符合人意的部分,或是需要修改的部分。
- 追问细节。对于我们和大模型有出入的地方,我们可以反问大模型,这不仅是在完善大模型的回答,也是在锻炼我们的思维。
- 限定格式。我们可以通过设定输出的格式,设定解析的格式对大模型进行限制。
目前,我们还不能完全相信大模型,当大模型给我们回答后,我们一定要对大模型的回答进行验证。
架构设计
本单元作业包含三个层次 Person -> Tag/OfficialAccount -> Network 。
考察了一组继承关系 Message <- EmojiMessage/RedEnvelopeMessage/ForwardMessage
通过JML给定了整个社交网络的基本功能规格,如何设计层次之间的交互方法甚至额外层次是本单元
作业的关键。
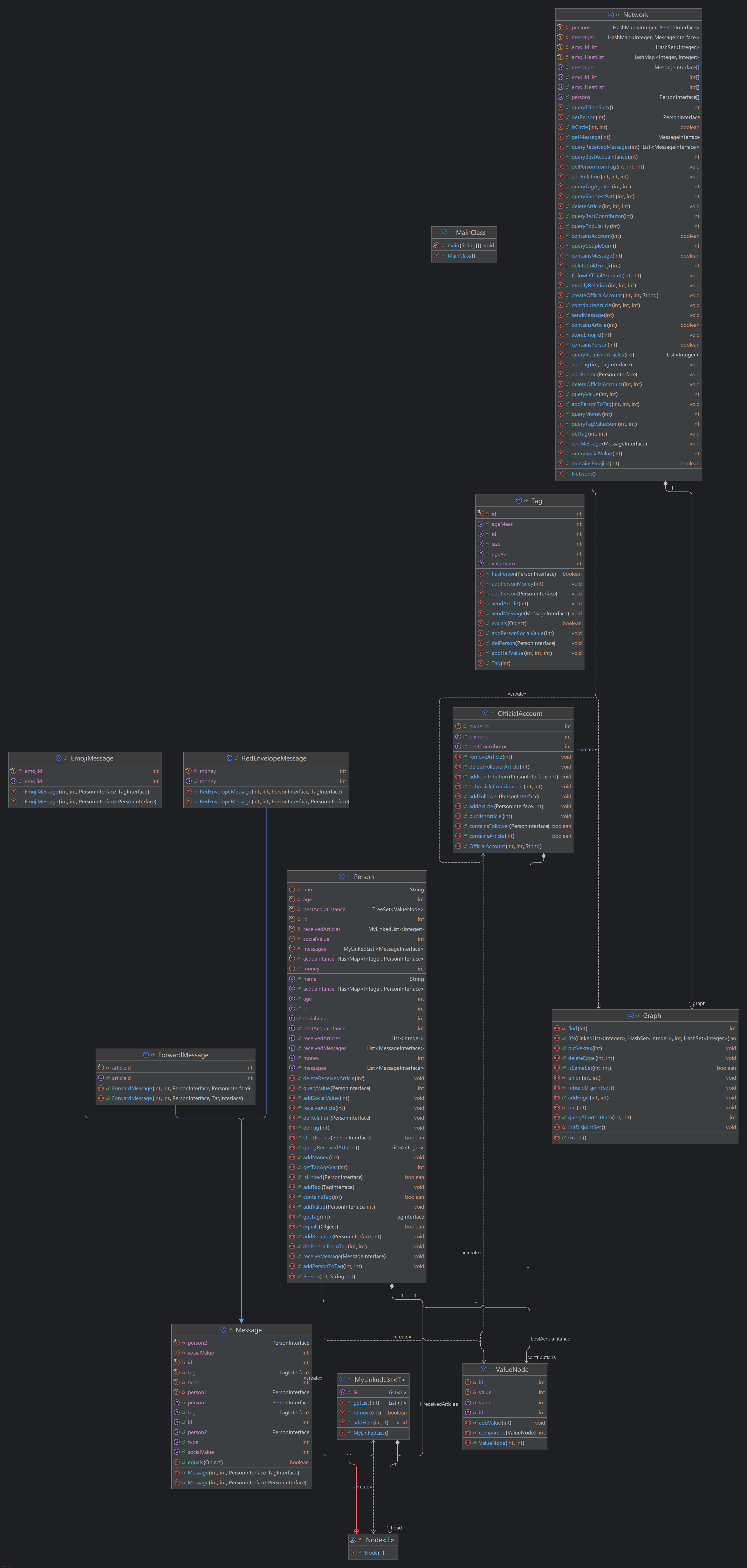 \
\
建模
Network 可以看作是社交关系网络的抽象,为图结构。 Person 和 Relation 可以分别看作是图的顶点和加权边。
每一个 Tag 可以看作是 Network 按照 Tag 所有者和内部 Person 为集合的生成子图。
每一个 OfficialAccount 可以看作是内部所有 Person 点构成的完全图。
在维护用户关系图时,我同时维护了一个对应的并查集辅助结构帮助查询。
图模型构建和维护
用户关系图
- 构建:
Network通过addPerson()方法增加节点, 通过addRelation()增加边- 增加边时同时调用并查集的
union()方法进行点的合并。
- 维护:
- 通过
modifyRelation()修改边的权重,边权小于0的边将会被删除。 - 删边时,需要对并查集进行重建。不过我在这里设置了脏位,在修改后的下一次查询连通性才进行重建。
- 通过
- 构建:
标签图
- 构建:
addTag()创建标签,声明一个图addPersonToTag()方法向图中添加节点,生成新的点的生成子图。
- 维护:
delPersonFromTag()从Tag中移除节点,生成新的点的生成子图delTag()删除图- 当本图增加点,删除点,增加边,修改边的时候,我们需要动态维护
valueSum属性,方便快速查询。 - 当本图增加点,删除点的时候,我们需要动态维护
ageSum和ageSquSum两个变量,方便快速查询年龄平均值和方差。
- 构建:
维护策略分析
- 延时重建:设置脏位或懒标签,在相关结构修改后不着急修改图的结构,下次查询时再进行修改。时间复杂度并没有发生变化,对于查询和修改交替频率不高的系统优化效果较好。
- 缓存数据,动态修改:对于相关的复杂图结构的查询时间复杂度较高,我们可以将查询的时间操0作分摊到增加、删除、修改中,通过修改同一个缓存数据实现动态修改。
- 采取合适的数据结构。可以在顶层存储点、边之间的关系,方便快速查询使用,用空间换时间。
作业问题
作业中出现的性能问题及其修复情况
本单元迭代作业中,我在hw10中出现了一个性能问题。
问题:在hw10的强测中,我 CTLE 了一个点,本地跑一遍后确定为 mr 删边后 qsp 时间花费太高。我原来的实现是通过 isCircle() 判断两个点是否连接,但是我 isCircle() 的实现在删边后需要重建并查集,再进行最短路查询,此时并查集重建花费大量时间。
修复:后面意识到并查集的思路不太适合作业,于是我将是否联通的判断并抛出路径不存在的异常放在最后。修改自己的双向广搜方法,让自己的方法在广搜过后,如果两个点没有联通返回 -1 作为标志,最后判断方法返回的结果判断是否抛出异常。
互测中遇到的性能问题,主要有:
qts使用三重循环,在ln 100与全qts查询的数据点下遗憾落败qtvs使用双层循环,有点危险的时间复杂度,通过哈希表卡常勉强CTLE,如果是在双层循环内部通过哈希相关的数据结构获取元素,则卡常对时间的影响更大了- 使用
Linkedlist数据结构导致删改的时间花费很大 - 判断是否重建并查集时使用
DFS算法深克隆获取点集id,哈希表卡常CTLE
规格与实现分离
规格是对一个方法/类/程序的外部可感知行为的抽象表示,是对设计正确性的逻辑化表示。它准确定义和表示方法行为的正确性。
类规格完整准确定义了一个类的设计目标和能力。
数据规格从外部使用者角度定义一个类所管理的数据及其需要满足的约束。
方法规格定义执行成功的前提条件和成功执行的效果。
也就是说,规则对方法的流程并没有特别规定,只特别规定了数据的外部表现形式和方法的执行结果。在满足了规格规定的后置条件、变量的约束和副作用后,我们可以自由选择实现的方式。
当然,自由并非随心所欲。规格建立于实际需求之上,实际需求可能对时间和空间有限制和要求,这使得我们需要在实现时选择符合要求的数据结构和算法。我们的实现仍然受到规格和现实需求的限制。
Junit
对于JML规格定义的方法,由于我们的实现基于JML规格,我们的实现需要满足JML规格,我们可以根据JML规格编写相关的Junit代码。
利用规格信息来更好的设计实现Junit测试
前置条件(pre-condition)
前置条件通过
requires子句来表示。Junit中,我们构造的数据需要满足前置条件,并且也需要覆盖尽可能多的前置条件。对于前置条件未定义的测试数据,我们不必关心其测试结果。
后置条件(post-condition)
后置条件通过
ensures子句来表示。当我们的行为满足前置条件时,我们需要检测前置条件对应的后置条件是否被满足。如果有多条
ensures子句,我们需要保证每一条子句都被满足。副作用范围限定(side-effects)
JML提供了副作用约束子句,使用关键词
assignable或者modifiable。在方法执行过后我们需要判断对象内所有属性的变化情况,方法是否只修改了子句允许修改的状态。在本单元的Junit中,我一般深拷贝对象,再将执行后的对象与克隆的对象进行比较。
正常功能与异常功能
对于
public normal_behavior正常功能,我们要保证方法正常执行,不抛出异常。对于
public exceptional_behavior异常功能,我们需要保证方法正常抛出异常,并且检测异常的类型是否符合JML要求。不变式与状态变化约束
一般来说,每次测试方法执行之后,我们需要对不变式和状态变化约束的属性进行检测。
pure表达式pure表示方法是纯粹查询方法,即方法的执行不会有任何副作用。我们需要特别关注副作用范围。
Junit测试检验代码实现与规格的一致性的效果
总体来说,JML为Junit测试指明了测试的内容和测试的要求,是连接开发人员和测试人员的桥梁。
由于我们的代码是根据JML进行实现的,我们需要根据JML构造Junit代码。当我们根据JML一条条实现 assertEqual 断言之后,我们也就能检测代码实现与规则的一致性。
具体实现
笔者会在这个部分写下自己的思考和程序具体实现思路。(可能这部分是最有用的吧)
与前几届不同的是,本届第三单元不需要自建异常类。代价是我们新增了 article 和 account 类相关的逻辑。
时间复杂度
虽然强测没有所谓的性能分,但是当你 CTLE 时,你拿不到一点分数。因此,这个单元除了正确实现JML规格之外,程序的性能也十分重要。
我不太清楚Java程序10s底下能跑多少条指令,但是根据学长们的思考和我的实践经验,以下大概是时间复杂度的上限
对于强测:O(nlogn) or O(VlogV) or 小常数O(E)
对于互测:大常数O(n^2) or O(n^2logn) or 常数比较大的O(E)
笔者的建议是实践出真知,强测前可以自己生成压力测试的数据本地进行测试,生成的数据也可以用于后面压力测试其他人的程序。
我在使用 IDEA 自带的 IntelliJ Profiler (以下简称 Profiler )进行运行时间分析时遇到过一些问题:
本地运行的时间不代表平台评测机运行的时间:受到硬件和软件的影响,程序在不同环境下运行相同数据的时间会有较大的不同。对于我的机器而言,强测
CTLE数据可能在本地只需要运行 4-5s,互测hack别人CTLE的点在本地需要运行到5s左右才能刀中人。建议大家找好本地测试的时间阈值。根据我和室友的运行比较,相同的程序和样例,花费大量时间的重点语句也会有些许不同。与此同时,
Profiler的时间统计的范围和统计对象我也觉得有点不准。对于我本地构造的一个样例,
Profiler提示时间主要花在(与Person增删无关的)删除文章语句中判断异常的方法containPerson()上,但是当我删除掉该方法后面的其他语句后,程序的时间反而大部分减少,并且containPerson()的时间花费也大幅度减少。
因此也不能完全相信 Profiler 的结果。
那么,我们应该如何降低我们程序的花费的时间呢?
- 换算法/数据结构,使用更高效的数据结构和算法。
- 动态维护变量。对于一些查询时间复杂度比较高的方法,我们考虑维护过程量或是结果,将查询时间分摊到增、删、改三种操作内。
- 在2步的基础上,我们可以设置脏位(标志位)。在增、删、改后并不直接修改中间属性的值,改为修改标志位,在查询前判断标志位的情况,再考虑是直接根据中间属性计算结果还是按照逻辑重新计算结果。但是这种方法并未直接降低时间复杂度,在极端情况下优化效果不太好。
具体实现思路
我们的操作可以分为四类:增删改查。其中增删改主要和我们具体选择的数据结构有关,不多赘述。由于本单元基于的数据结构是图,我们查询的内容都是比较复杂的图结构的数量或值,因此我们程序花费的时间主要都在查询操作上。
query_value/qv:查询边权,可以直接查询Person对象内部属性即可。query_circle/qci:判断两个节点是否处于同一连通分量。常见做法有两种- 使用并查集结构辅助判断。并查集主要的功能是并和查。但是删边对并查集的影响较大,删边时如果直接重建,时间复杂度可以达到
O(E*alpha(V) + V),根据我的惨痛教训,如果数据出的比较强的话在强测中会被卡住。如果选择这种方法,需要通过其他判断边是否为桥、连通块染色重建、设置脏位来降低重建时的时间花费。 - 使用图查询算法查询。
BFS和DFS均可,算法并不复杂,最差时间复杂度为O(E)。也可以使用双向BFS降低平均时间复杂度。推荐使用。
- 使用并查集结构辅助判断。并查集主要的功能是并和查。但是删边对并查集的影响较大,删边时如果直接重建,时间复杂度可以达到
query_triple_sum/qts:查询用户关系图上三元环的数量。- 朴素算法,根据JML的算法,时间复杂度为
O(V^3),如果运行大量qts则一定会超时。 - 我采用的方法是动态维护中间变量,直接维护图三元环的数量。当图增边或删边时,判断操作的边能否和其他边构成三元环,从而增加或删除边的数量。我的做法是取
id1和id2的acquaintance,将取出的临界点集合用retainAll()方法取交集,交集的基数即为修改的三元环数量。
- 朴素算法,根据JML的算法,时间复杂度为
query_tag_age_var/qtav:查询特定tag内所有人年龄的方差。- JML规格提供的算法的时间复杂度为
O(V^2)。如果在循环前获得ageMean(),在循环中复用的话时间复杂度为O(V),已经符合时间复杂度要求。 - 我的实现是维护
ageSum和agePowSum两个中间变量,在Tag中增加人、删除人时修改两个中间变量的值。最后调用该查询方法时返回agePowSum - 2 * mean * ageSum + personsCount * mean * mean) / personsCount)即可。 - 如果采用维护中间变量,需要特别注意的是,我们采用的除法是向下取整的,我们需要严格按照推导出的恒等式进行计算。
- JML规格提供的算法的时间复杂度为
query_best_acquaintance/qba:查询特定用户的最好朋友。可以遍历acquaintance求最值,时间复杂度为O(n),但是不建议,原因会在后面的查询语句中提到。具体实现时我增加了脏位维护。query_shortest_path/qsp:字面意思是查询最短路径,实际是查询联通两个点路径经过的最少的点的数量,也是将原来的用户关系图的权值都变为1时的最短路径。我最终采用的方法是双向BFS判断连通性+求得最短路径,时间复杂度为O(E)。原来我是采用
isCircle()方法判断两个点是否连通(因为要抛出异常),但是- 我在双向
BFS前调用isCircle()判断是否连通 - 我的
isCircle()在一定条件下要重构并查集 - 并查集重建时每条边
union()两次,常数过大
导致最差情况下该查询方法的时间复杂度过大,hw10中出现了性能问题
- 我在双向
query_best_contributor/qbc:查询officialAccount中贡献最大的贡献者。遍历求最大值,时间复杂度为O(V),我额外做了一个脏位维护。query_received_articles/qra:查询某一用户最近五篇接收到的文章,如果没有五篇则返回所有接收到文章。方法和具体选用的数据结构有关,这里我放在后面讲吧。query_tag_value_sum/qtvs:查询Tag关系图中所有边的权值和。- 采用JML规格的算法,时间复杂度为
O(V^2)。如果完全按照JML规格的方法进行实现,互测创建 600-700人的Tag后查询应该是可以被hack到的,如果进行常数优化,内层循环初始定义j = i + 1的话也有机会被hack到。 - 我采用的方法为在每个
Tag内动态维护valueSum。在Tag加点、删点,用户关系图增边、删边、修改边的权值时都需要修改valueSum的值。
- 采用JML规格的算法,时间复杂度为
query_couple_sum/qcs:查询互为最佳好友的一对用户的数量。- 采用JML规格的算法,时间复杂度为
O(V^2) * O(”qba“)。 - 我采用的方法时遍历求值+脏位维护。我直接遍历
Persons数组,然后判断其bestAcquaintance的bestAcquiantance是否为自己,由于直接遍历,遍历时大量运行的bestAcquaintance()最好降为O(1),所以我的程序在person.bestAcquaintance()中设置了脏位维护,qcs除第一次外调用重复用户的bestAcquaintance()的时可以以O(1)的时间复杂度获得结果,最终分摊下来的时间花费还在要求内。由于这个方法的最差时间复杂度比较高,保险起见,所以我还设置了脏位。
- 采用JML规格的算法,时间复杂度为
query_social_value/qsv:查询某一用户的社交值,直接返回值即可。query_received_messages:查询某一用户最近五条接收到的消息,可以参考qra,消息的逻辑比文章的逻辑更简单,所以这个指令的问题也不大。query_popularity/qp: 查询某一表情的人气值,同qsvquery_money/qm:查询某一用户的余额,同qsv
本次作业对空间卡的并不死,可以用空间换时间,可以尝试多用一些 Hashmap 存储一些值,简化查询流程。
对于本年新增的 article 相关逻辑。对于 article 的查询,我们需要在存储数据的同时也要存储插入顺序,在hw11中容器内部的 articleId 也可能会重复。我在本次作业中见到以下几种:
LinkedList不推荐使用,很多使用该数据结构的同学都在hw10超时了。疑似是删除链表尾部的元素时cache会疯狂不命中导致CPU时间很长。ArrayList可以用,hw10应该是不会超时。但是疑似hw11如果使用removeif()方法进行删除文章可能会超时。- 自定义数据结构。类似数据结构的链表,定义有前后指针的节点结构,用指针记录头节点,用
HashMap记录存储articleId相同的节点的容器。这样插入、删除和查询都有比较好的时间复杂度。
Hack
本单元我Hack的重心并不在评测机评测上,大部分互测时间我都在代码走查,看别人的代码。
想要找Bug的话,可以找自己的室友或是小伙伴相互代码走查一下,然后再深入交流,修改不足的地方。
这个单元,我们都按照JML规格进行编写,实现方法大部分都在往年的总结和代码里看到影子,逻辑并不复杂。因此,这个单元代码走查的速度还是挺快的,不需要花费大量时间理解别人的代码。
同时,一些细节也只能在代码走查时看到,比如 Tag 的 Person 容量1000,如果只是通过3k/1w条指令的随机生成器生成,概率也是比较低的。同时,在代码走查的过程中你也可以看到别人时间复杂度不合理的地方,这部分也不需要细看,只需要每个方法快速扫一眼即可。
我的互测比较坎坷,第一次因为某个脏位维护的逻辑错误掉到了B房,后面两次都在A房,但是第二次 CTLE 了一个测试点。
第二次互测时,遇到两个关于 Tag 中 getValueSum() 双层循环的实现:
// exmaple_1
public int getValueSum() {
long sum = 0;
ArrayList<Integer> k = new ArrayList<>(persons.keySet());
for (int i = 0; i < k.size(); i++) {
Person pi = (Person) persons.get(k.get(i));
for (int j = i + 1; j < k.size(); j++) {
Person pj = (Person) persons.get(k.get(j));
if (pi.isLinked(pj)) {
sum += pi.queryValue(pj);
}
}
}
return (int) sum * 2;
}
// example_2
public int getValueSum() {
int sum = 0;
for (int i = 0; i < persons.size(); i++) {
for (PersonInterface person : persons) {
if (persons.get(i).isLinked(person)) {
sum += persons.get(i).queryValue(person);
}
}
}
return sum;
}判断一下复杂度,两个实现都是 O(V^2) ,甚至 example_1 一条边只计算一次,计算的次数更少。
但是 example_1 在循环中调用了 persons.get() 方法,这是一个 HashMap 的获取 key 对应 value 的方法。同时, isLinked() 方法也是调用的 HashMap.containsKey() 方法。理想情况下这些方法的平均时间复杂度为 O(1) ,但 O(1) 并不意味着这个方法花费的时间很低,只是说明方法的运行时间与问题规模无关。双重循环导致 persons.get() 和 isLinked() 方法执行的次数很多。
实际情况下,两个方法的最坏时间复杂度为 O(log n)(内部通过红黑树实现)。我们如何增大其中的时间消费呢?对于 HashMap ,我们可以尝试使用哈希碰撞,人为构造特定的 key 序列,使得所有 value 都存在同一个桶内,将 HashMap 退化为红黑树,增加增删改查的时间复杂度。
具体而言,我们可以尝试使用 65537 的倍数作为 key 的 hashcode() 。在我提交的数据中,我的 personId 均为 65537 的倍数。
我们基于Java的 Profiler 进行分析哈希碰撞对程序CPU运行时间的影响。在同时采用 Tag 中700人,反复查询 qtvs 的情况下。第一个样例的运行时间可以从2.7s增加到9.1s,第二个样例的 isLinked() 方法的运行时间从2.7s提升至4.1s。
同时,在hw11中,我的室友在判断是否需要重建并查集时深克隆了 persons 的 id 到 HashSet 中,也是靠哈希碰撞hack到了。
Junit测试
我是依靠第一次实验给的随机生成数据的格式,自己写了生成器随机生成需要使用的图的属性,然后通过10组随机生成的数据进行Junit测试。
关于正确性判断方面,我们只需要根据JML规格中 ensures 子句的条件进行编写即可。特别要注意 pure 关键词自带的意义。
一些小细节
- 一定要检查自己的程序是否覆盖所有抛出异常
Tag中人数限制deleteArticle()时删除所有articleId为目标id的对象
学习体会
通过本单元JML的历练,我对契约式设计的理解更加深刻了。规约设计思维的核心是首先提出并规定预期结果所满足的约束,然后才会有过程式算法实现。
当我们在照着JML写代码的时候,我们会感叹JML怎么这么麻烦,通过这么繁琐的约束描述了一个这么习以为常的功能(也可能是目前需要的功能并不复杂)。但当我们在实验课上自己写JML的时候,又头疼如何能精确、无二义地描述自己的要求。这两边还都是十分矛盾的。
虽然根据JML进行实现比较复杂,但是实现的过程也是比较顺利的,并且在接口之间的设计、协作是比较方便的,测试的功能和目标也比较明确。这是JML的优点,也是写代码前充分设计的优势。
在阅读和编写JML的过程中,我也是逐渐体会到了设计和实现不同之处。
感谢在研讨课和讨论区分享思路和架构的同学们。感谢助教和课程组的帮助和陪伴。
后记
也没想到这篇文章会在电梯博文之前完工。这篇文章没有图片,看起来还是比较费劲的。
这个单元的工作量也还是不大的,而且学期进展到这个时间,大部分急事也已经忙完了,压力也比较小。希望大家能享受JML规格和第三单元吧。

