BUAA-OO Unit.1 Hw4 作业总结和分享
关于这篇文章
- 这篇文章只适用于北航2025OO课程,每年的指导书内容可能会有变动,具体内容请以当时课程为准。
- 这篇文章主要是记录我在OO-Unit1期间的一些记录、思考,仅作为参考,希望对读者有所帮助。
- 这篇文章是在hw4期间写的。受限于作业的要求,csdn上提交给课程组的版本会有删改。如果想要了解OO-Unit1的话可以直接阅读这篇文章。
- 如果这篇文章涉及学术诚信以及神秘问题,请与我取得联系,我将及时修改。
前言
本单元的主题是 递归下降 。
本单元的背景是 表达式解析 。
最终架构与分析
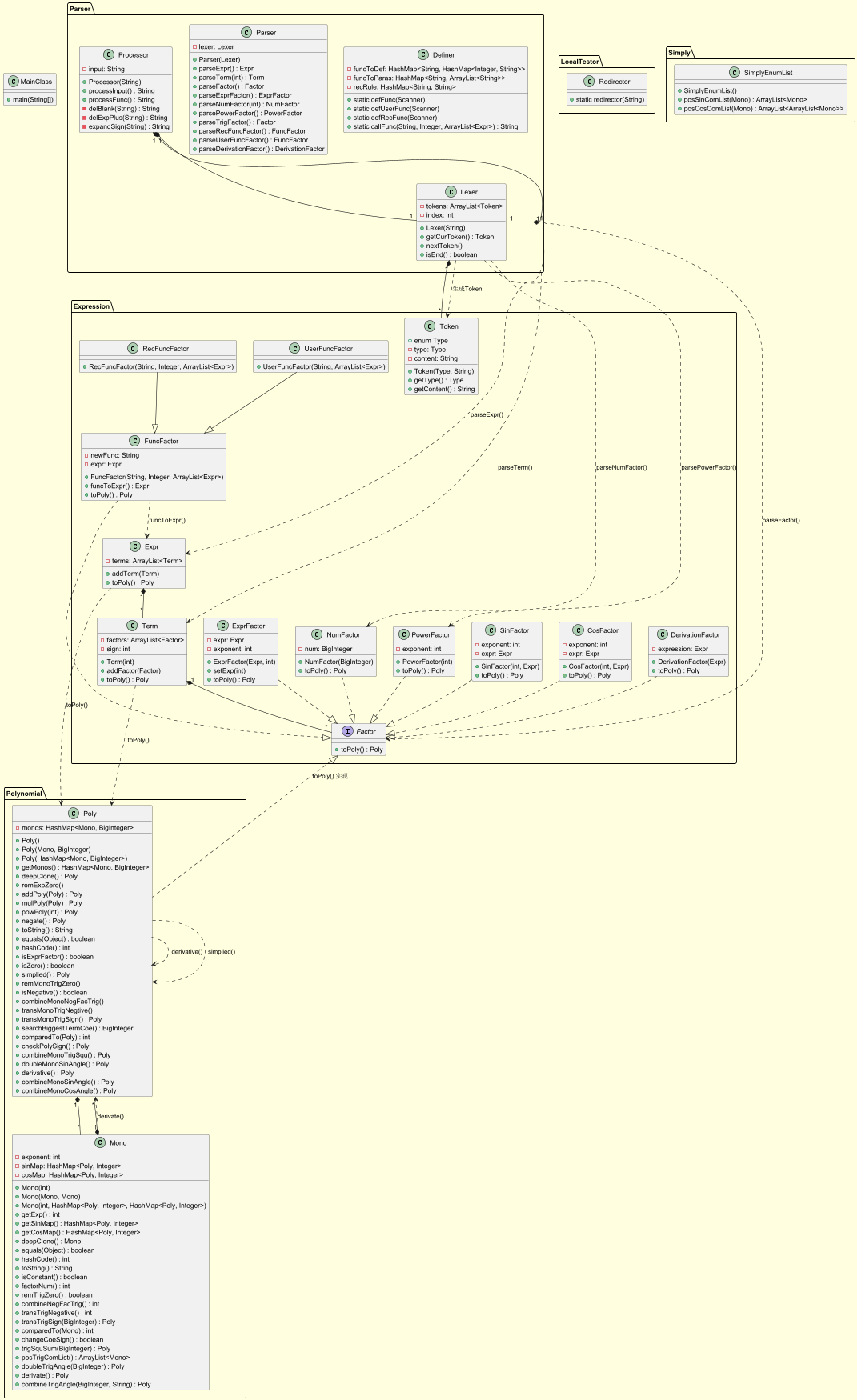
UML类图
量化分析
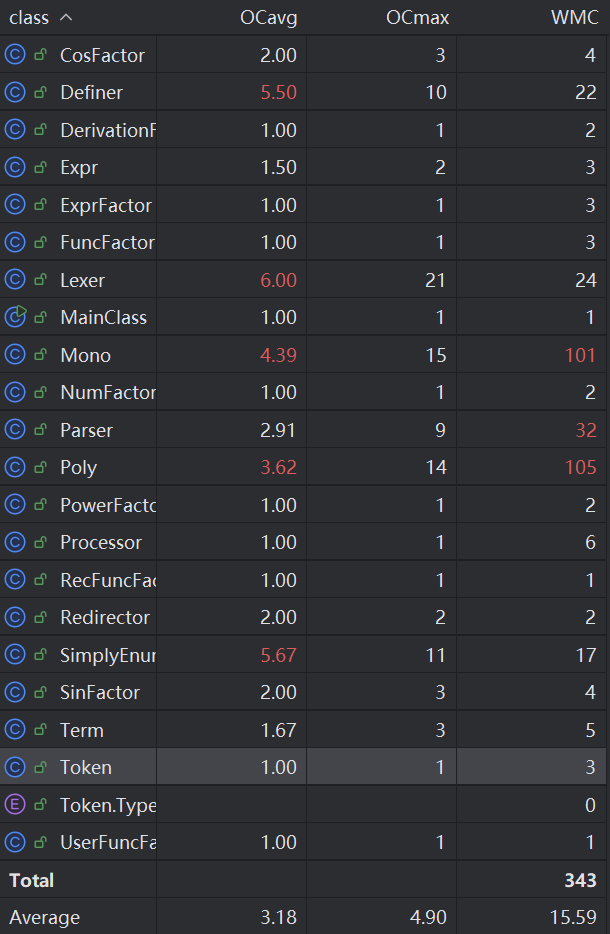
可以发现,类复杂度分布不均。其中 Poly 、 Mono 、 Parser 类的WMC值较高,分析原因是因为 Poly 和 Mono 类内部有关三角函数化简的方法复杂度过高, Parser 类内部解析方法的条件判断分支过多,复杂度高。可以考虑将三角函数化简方法移到新的化简类中,分解方法内部的逻辑。
关于IDEA的statistic插件我使用不了,解决无果
我的 Poly 类中有27个方法,代码有461行, Mono 类中有20个方法,代码有438行。其中部分方法方法可以进一步解耦,减少两个核心类的代码规模😢。
架构设计总结
表达式预处理与词法分析
Processor类:对输入的字符串进行预处理,按去除所有空白字符、去除^后的加号、将所有+和-符号分别替换为+1*和-1*。Definer静态类:用于处理自定义函数和递推函数的输入、调用。内部存储函数调用的表达式,调用函数时将表达式内部的形参替换为实参,返回替换后的表达式。Lexer类:用于将处理好的字符串转化为Token流。转化时主要根据预设的关键词和字符的形式进行合并。
表达式语法解析
Parser类:根据文法调用其中不同的paser()方法,将Token流转换为对象。Expr、Term和Factor类:分别对应文法中的表达式、项和因子,内部使用ArrayList进行存储,以便后续转化。Factor接口:实现多种因子的统一处理,增加复用能力。因子包括NumFactor、SinFactor、CosFactor、PowerFactor、DerivationFactor、RecFuncFactor、UserFuncFactor,分别对应常数因子、正弦函数因子、余弦函数因子、幂函数因子、求导函数因子、递推函数因子、自定义函数因子。
表达式合并化简
通过所有
Expr、Term和Factor类的toPoly()方法,将解析后的表达式统一化为Poly和Mono类的组合,以进行进一步处理。Mono类:单项式类,内部用两个HashMap存储三角函数因子内部对应的指数。Poly类:多项式类,内部用HashMap存储Mono对应的系数。当HashMap为空时,默认Poly = 0.Poly类内部Simplied()方法是三角函数化简的入口,在该方法内部按顺序调用其他化简方法。
迭代设计
第一次作业
需求分析:
读入一个包含加、减、乘、乘方以及括号(其中括号的深度至多为 1 层)的单变量表达式,输出恒等变形展开所有括号后的表达式。
设计思路:
- 如何将输入的表达式处理成我们(或是程序)更好理解的形式,也就是应该进行什么预处理。当时是借鉴了jby学长的处理方法,方法同架构设计总结中一致,尝试将所有的符号下降到常数因子层面统一处理。但是发现有的时候项和项之间的符号还是可能会是符号。可能的解决方法是将
-转化为+1*-1,但是笔者觉得可能会把表达式弄的太复杂,同时额外的时间开销也很大。于是还是在paserTerm()方法中新增了一个参数用来传递该项符号的信息,最后在toPoly()的过程中再进行符号处理。 - 如何处理表达式。这里借鉴了实验课及先导课Hw7的代码,尝试使用
Lexer、Parser,将字符转化为Token流,再将Token流转化为Expr、Term和Factor的三者之间的关系,最后通过它们之间的关系,将对象统一转化为Poly和Mono类。 - 如何抽象表达式信息的层次,组织类之间的关系。在
Parser类,我们仅是将Token流转化为Expr、Term和Factor,而我最终处理表达式的逻辑应该放在Poly和Mono中,在Expr和Term类中仅需要理清对象的包含关系,因此我选用ArrayList存储。至于Mono的系数,我纠结了很久,究竟是放在Mono层面还是Poly层面,最终我把Mono类定义为多项式中的基础单元,因此把系数放在Mono外,而在Poly中,使用HashMap能比较快速和清晰地胜任多项式合并的功能,因此我选择用HashMap组织内部Mono。 - 如何输出性能最高的形式。由于Hw1
Mono形式比较简单,为,这里我只重写了 Poly和toString()方法,通过调用Poly的toString()方法统一输出。
- 如何将输入的表达式处理成我们(或是程序)更好理解的形式,也就是应该进行什么预处理。当时是借鉴了jby学长的处理方法,方法同架构设计总结中一致,尝试将所有的符号下降到常数因子层面统一处理。但是发现有的时候项和项之间的符号还是可能会是符号。可能的解决方法是将
第二次作业
迭代需求分析:
- 支持嵌套括号
- 支持三角函数因子
- 支持递归函数
设计思路:
对于嵌套括号,我们第一次架构就可以处理递归下降的结构,因此无需修改过多架构。测试出现Bug过后再进行修改即可。
对于三角函数因子,我们需要在
Lexer和Token内部注册新的关键词,并且新建三角函数因子类,在Parser内部新增对应类的解析方法。新增三角函数后,我们
Mono的形式也发生了改变,这里我采用HashMap存对应三角函数内部的Poly及其对应的指数。同时,我们的toString()方法也变的更加复杂,这里我新增了Mono类的toString()方法,将Poly内的逻辑部分整合进Mono内部,通过通过Poly和Mono的toString()方法相互调用构建表达式的形式。同时,为了使自己程序的性能分更高,我们还需要对多项式进行化简优化,具体实现见 我的优化 。
对于递推函数,这是往届未出现过的功能。但是我们可以将递推函数看成一个函数列,它只是比往届的自定义函数多了一个
n,也就是我们需要根据它在函数列的位置调用不同的表达式,当n == 0/1时,它的功能和自定义函数是相同的,当n>2时,我们调用的是一个带递推函数调用的表达式,我们可以再将该表达式进行语法解析,得到新的、阶数更低的表达式。当然,也可以先将n=0,1,2,3,4,5时候的表达式都提前处理存储起来,解析表达式的时候进行变量替换即可。这里我建立了一个新的静态类
Definer进行函数的定义和调用。
第三次作业
- 迭代需求分析:
- 支持自定义函数
- 支持求导运算
- 设计思路:
- 对于自定义函数,如第二次的设计思路所言,自定义函数和递推函数是有共通点的,这里我将Hw2中的递推函数因子抽象成了一个新的类,将新的自定义函数因子和递推函数因子都继承这个因子,只是自定义函数因子自定义时默认
n = 0,这样新的自定义函数,再稍微修改一下之前Definer,定义自定义函数时没有递推公式,这样就可以直接复用之前的接口和代码。 - 对于求导运算,笔者觉得求导运算不应该放在
Parser类的逻辑中,Parser类仅作为解析语法,链接 Token流和Expr的桥梁,因此我将求导运算放在了Poly层面,在处理求导函数因子的时候,我们可以先调用内部Expr的toPoly()方法得到Poly,再调用Poly的derivative方法得到求导因子转化为Poly的方法。这里根据之前文章中提过的Poly的结构,我们还需要写Mono的derivative方法,二者相互调用得到最顶层Poly的求导结果。
- 对于自定义函数,如第二次的设计思路所言,自定义函数和递推函数是有共通点的,这里我将Hw2中的递推函数因子抽象成了一个新的类,将新的自定义函数因子和递推函数因子都继承这个因子,只是自定义函数因子自定义时默认
新的迭代场景
- 新增新的数学特殊因子,如
e、pi、i。我们可以在Token、Lexer和Parser中注册,并且在Mono层面新增对应的无理数名称到其指数的HashMap,这里可能还需要修改toString()方法,三角函数化简方法等。 - 新增除法,也就是系数、指数可以为分数,这里我想的是将原来存储指数或者的HashMap的key从BigInteger改为
Fraction,其中Fraction是新增的分数类,内部属性有符号位、分子和分母,我们需要写Fraction类的相加,相乘方法。 - 新增新的函数,如指数函数,我们的迭代方法也是和第一点差不多。
我的优化
先讲一下我这边程序运行速度优化的情况,官方的CPU时间限制是10s,Hw3强测数据点中最多的CPU时间为0.86s左右。个人感觉强测的CPU运行时间卡的并不死,给了程序很多可以进行优化的空间。
感觉Unit1的优化主要在性能优化上,主要讲讲自己做的(不显而易见的)性能优化:
输出格式性能优化
- 调整输出顺序,根据系数由大到小的顺序组织单项式进行输出
- 判断三角函数内是否为表达式,如果是表达式则输出时候表达式两边需要额外增加必要的括号
- 输出结果时判断所有项系数是否全为负,如果全为负尝试将某项的符号放入项的三角函数内,腾出一个正项
三角性能优化
我是保守派,只做了一定能缩短输出字符串长度的优化。
在Hw2时,我做了以下三角函数(嵌套)优化:
- 出现三角函数中多项式全为负的情况时,尝试将符号从三角函数内提取到三角函数外,缩短三角函数内部多项式的长度
- 定义Mono和Poly的大小关系,将Poly中最大的Mono的系数的符号作为该Poly项的符号,所有Mono三角函数内部的Poly符号统一,以便后续哈希表合并同类项以及化简
- 三角函数内部多项式为0的情况
- 合并所有可以合并的同类项,例如
- 三角函数平方和,不考虑系数的狂暴合并
, $3sin^2(x)-2cos^2(x)=5*sin^2(x)-2$ - 有条件的正弦函数二倍角化简,例 $(c2^m)sin^n(x)cos^n(x)=(c2^{m-n})sin^n(2x)(m>=n)$
在Hw3时,我做了以下三角函数(嵌套)优化:
- 三角函数和角公式$c(sin(x)cos(y) \pm sin(y)cos(x))=csin((x \pm y))
c(cos(x)cos(y) \pm sin(x)sin(y))=ccos((x \mp y))$
分析
你的优化能否保证你代码的简洁性与正确性?感觉不能。我优化的过程中主要还是面向过程的思想,也可以说我不清楚如何将化简的过程抽象为面向对象的思想。
可能的解决方案,可能是将多个化简方法中共有的代码功能块抽象为新的方法,或者是将化简方法移动到专门用来处理化简的类中。
我的理解和实现细节
关于结构的抽象以及数据类型的选择
为了方便理解,我们先约定和明确几个关键词:
单项式:
Mono,在Hw3中,我的实现形式为多项式:
Poly,在Hw3中,我的实现形式为同类项:单项式和单项式的相等恒成立,可以进行合并的单项式。
不同人有不同的想法。这里我参考的是本年实验、先导课中提供的代码结构和学长们的思路。程序的数据流变换过程如下:$String \rightarrow Token \rightarrow
后面在思考Hw3作业时,感觉其中表达式、项和因子三个类仅是作为过渡用的类,甚至可以删除这三个类,直接根据语法将 Token 转换为 <Poly, Mono> 。但是最后没做,懒。主要是因为这样会让原来三个类的代码放入 <Poly, Mono> 之间,导致结构功能有点繁杂。
荣老师说程序接口的命名最好是写成 -able 后缀的形式,我的理解是这样便于程序员程序编写,可以根据命名直接看出继承接口类的方法和逻辑。但是我这里接口的名字是 Factor ,主要是从语法的角度出发的,最后也没从这个接口抽象出具体的方法和逻辑,仅作为 Term 类转换为 Poly 类时调用不同类型 ~Factor 类标准入口。
不同思路实现的细节不同。关于 <Poly, Mono> 的具体实现,我的想法是:
选择
HashMap实现类的层次抽象Mono类的形式不包括系数,也就是Mono类内部不存储其在多项式中的系数即使两个
Mono对象是等价的,我们在equals()方法中仍认为二者是不相等的e.g.
sin((x-1))与sin((1-x)),我并不会实现类似”负相等”的equals()方法
关于为什么要选用 HashMap :
HashMap是无序表,和ArrayList比起来,插入HashMap的顺序并不会对HashMap的比较产生影响。- 个人感觉便于最后
toString()方法的编写,默认不会出现相同的项,便于同类项合并。 - 看到了学长们博客中提到很多关于
HashMap方法,数据处理方便,不重复“造轮子”。
关于为什么 Mono 类为什么不包括系数?当然,包括系数的实现也是可以的。我的实现是我的个人偏好,我偏向于认为 Mono 类只是对单项式“形式”的模拟,与系数无关。
关于”负相等”的 equals() 方法作为 HashMap 的合并方法,我在考虑包含三角函数因子的 Mono 同类项合并时曾考虑过这个方法。我的一个室友采用的是这个方法,也应该说这个方法是可以的。对于我来说,这个方法有几个需要深入思考的问题:
我们考虑两个负相等的同类项 sin((x-1)) 与 sin((1-x))
- 合并后,我应该在两个相反的多项式中选择哪一个形式作为合并结果的形式
- 合并时需要得到合并后的系数,这里我们的系数和第一个问题有关,同时,在合并时系数的运算和单项式的系数也有关系
个人感觉,以上代码逻辑有点复杂,具体实现涉及到单项式和系数的协作,我的架构实现并不方便,同时我也觉得比较容易出现错误,可能还有潜在的问题,因此我并没有选择这种方法。
以下是我 Mono 与 Poly 类的具体架构。我采用的都是HashMap结构。
// Poly.java
public class Poly {
private HashMap<Mono, BigInteger> monos;
}
// Mono.java
public class Mono {
private int exponent;
private HashMap<Poly, Integer> sinMap;
private HashMap<Poly, Integer> cosMap;
}在学长学姐的启发下,合理运用foreach()方法、lambda表达式和merge()方法可以使得 Poly 的相加、相乘的方法变得十分简洁。
如果想要合并同类项,我们可以考虑用对让其中一个HashMap使用foreach()方法,然后对另外一个HashMap使用merge()方法,将foreach()取出的每一对键值对执行指定的操作。
需要注意的是,merge()方法在向HashMap合并的过程中,如果key不存在,不会调用重映射函数。因此不建议用 BigInteger::subtract 等减法方法作为重映射函数。建议将插入的值取反,然后使用加法方法作为重映射函数。
示例如下:
public class Poly {
...
public Poly addPoly(Poly other) {
Poly resPoly = this.deepClone();
other.getMonos().forEach(
(key, value) -> resPoly.getMonos().merge(key, value,BigInteger::add));
resPoly.remExpZero();
return resPoly;
}
public Poly mulPoly(Poly other) {
Poly resPoly = new Poly();
for (Mono monoX : monos.keySet()) {
for (Mono monoY : other.getMonos().keySet()) {
BigInteger coeX = monos.get(monoX);
BigInteger coeY = other.getMonos().get(monoY);
resPoly.getMonos().merge(
new Mono(monoX, monoY), coeX.multiply(coeY), BigInteger::add);
}
}
resPoly.remExpZero();
return resPoly;
}
...
}如果采用 Poly Mono 自定义类作为 HashMap 的key的话,我们需要可能重写 equals() 方法和 hashCode() 方法。
具体原因我们可以参考 HashMap 映射的实现方式,我在这里不多赘述。
在后面迭代时,我的理解中,需要注意的细节和可能出现的问题有:
- 如果架构中
Poly和Mono并不是不变类,也就是我们之间对Poly和Mono对象的属性进行修改,并且修改后的对象与之前的对象hashCode()并不相同,HashMap并不会动态更新。这样可能不能做到合并同类项的功能。 - 深浅克隆的问题。同1,如果
Poly和Mono并不是不变类。如果是浅克隆可能会出现两个Mono对象公用同一个Poly对象,在Mono(A)对象修改该Poly对象时候,可能会导致另一个Mono(B)对象的该Poly对象修改。
输出结果的方法
大多数人(包括我)都是重写 Poly 的 toString() 方法,这样IDEA在debug模式的时候也可以调用 toString() 方法,显示对象的信息,方便调试。
这里需要注意的是,重写的输出方法里最好不要有 side-effct ,不要修改类内的其他对象。
我同时重写了 Poly 和 Mono 的 toString() 方法,通过两个方法的递归调用实现各自功能。为了确保最后的输出长度较短,我们需要去掉一些不必要的括号和符号,因此在 toString() 方法中我还调用了其他用于判断的方法。具体我做的优化可以看前文内容。
如何合并三角函数同类项
由于三角函数有很多公式变换,因此同类项的形式有很多很多种。
这里我的方法比较笨,我是根据固定的公式变换,一步步根据公式将三角函数的形式进行统一,降低三角函数的复杂度(也就是“级别”),尝试将所有三角函数级别都降低到最低,最后通过 HashMap 进行合并。
如何合并三角函数“一级同类项”
之前讲的“负相等”方法可以通过 HashMap 进行“一级同类项”的合并,也就是不通过其他三角函数公式的变换,仅有 -1*sin(x) = sin((-x)) 与 cos(x) = cos((-x)) 实现三角函数内部多项式的正负号与高层单项式前系数的正负号进行转换。
我尝试统一所有单项式内部的多项式的符号(也就是除了最高层/最终输出的多项式之外的所有多项式)。
我们先考虑简单的形式,多项式是一个单独的三角函数因子,三角函数内部一定有
也就是要么多项式直接相等,要么将一个多项式取反和另一个多项式相等。这里仅涉及符号的转换。
因此我尝试定义多项式的符号,并且在这种定义下统一所有三角函数的符号,统一后的三角函数丢回 HashMap 进行合并,调用 equals() 方法,实现一级同类项的合并。
按照这个思路,我们要实现的目标是:使得统一后的三角函数合并做到,如果三角函数可以合并,一定是
我的定义如下:
Poly的正负性:Poly中最“大”的Mono前的系数的正负号Poly的大小:- 先调用
equals()方法,如果二者不相等在进行进下一步判断。 - 去除
res中系数为0的单项式,我们取处理后的多项式中最“大”的Mono前的系数,如果系数大于0,也就是,则有 ,如果系数小于0,则有 ,这一步不存在
- 先调用
Mono的大小:- 先调用
equals()方法,如果二者不相等在进行进下一步判断。 - 计算
- 先比较
x的系数的正负号,若则 ,若 则 ,否则进行进下一步判断 - 再比较
sin(x)项。我们先判断两个项HashMap是否相等,如果相等则进下一步判断。否则去除res中指数为0的sin(x)项,取剩余sin(x)项内部Poly最大的一项,判断其指数的正负号,若指数为正,即,则有 ,若指数为负,则有 - 再比较
cos(x)项。去除res中指数为0的cos(x)项,取剩余cos(x)项内部Poly最大的一项,判断其指数的正负号,判断方法同Step4,这一步不存在
- 先调用
我们可以证明,Poly ,我们一定能得到其正负性,从而调整其符号满足上述我们的目标
这几个定义相互耦合,但是由于我们的 Poly 和 Mono 的层数都是有限的,调用判断方法的过程也就是一个类似递归下降的过程,不存在无限递归的情况。
在调用转换正负号方法的时候,也是一个化简的过程,为了化简充分,应先调用自身的转换方法,先将自身内部的项化简后,在进行自己的化简。
调整三角函数内部 Poly 时记得考虑三角函数的类型和指数,余弦函数可以直接取符号,正弦函数在指数为奇数的时候需要调整系数的符号。
项和项协作的公式化简
如果是多个单项式合并成同一个单项式的公式,如 cos(x)*cos(y)-sin(y)*sin(x)=cos((x+y)) ,我参考了“两数之和”的哈希表实现方式,尝试查询是否有符合公式的两项,如果找到则将两项系数进行运算,并且将公式结果插入多项式中。
我采用的模板是:
- 遍历每一个
Mono,枚举得到该单项式可以提供的可能的项,其余部分作为合并时的共同部分。 - 根据遍历出的结果,转换形式得到,如果原单项式可以合并,则另一个单项式的形式。将结果放入一个表内返回。
- 从枚举这个返回的表中所有的单项式,作为key从前缀表(哈希表)中查找,如果查找的到,则说明该单项式可以和其他单项式进行合并,取出该项进行合并处理。
- 将合并后的结果放入前缀表,遍历下一个
Mono
如果公式前带有系数,我们还需要考虑系数是否满足情况。
使用这种方法,我们的重心就放在了枚举可能的同类项,得到另外一项单项式和结果单项式的构造。个人感觉这种查找方法实现公式还是比较机械的,但是我没有想到可以很好的复用代码的实现方式,所以我只用这个方法写了少许几个方法实现。
需要注意的是,不完全的公式合并可能并不能使得结果多项式的长度变得更短。如 3*cos(x)-1=cos(x)+cos((2*x)) 。
我的想法是保守合并,在使用公式合并时选择一定能缩短多项式的方式,但这样也可能导致原来的多项式不能通过两个不同公式合并成最短形式的多项式。我后面想到,也许可以参考 toString() 方法写计算性能的方法,然后再写拆公式的方法,最后比较拆和不拆的性能,选性能较高的结果。
化简程度
我觉得化简程序包括两个方面:
- 同一个公式的多次化简,e.g.
4*sin(x)*cos(x)*cos((2*x)) - 不同公式的化简顺序
对于多次化简,我参考了评论区大神们的实现方式,尝试使用缓存表存储每轮化简后的结果,然后在一轮化简后检查是否产生新的结果,如果没有产生新的单项式,则化简完毕,否则将新的结果作为初始对象,再进行新一轮化简。大概流程如下
public class Poly {
...
public Poly simply() {
HashMap<Mono, BigInteger> preMonoMap = new HashMap<>();
HashMap<Mono, BigInteger> rangeMap = new HashMap<>();
HashMap<Mono, BigInteger> buffer = new HashMap<>();
[处理Mono的化简,化简后的结果作为rangeMap]
boolean isEnd = false;
while (!isEnd) {
isEnd = true;
for (Mono mono : rangeMap.keySet()) {
if (find) {
buffer.merge(...);
isEnd = false;
} else {
preMonoMap.merge(...);
}
}
rangeMap = buffer;
buffer = new HashMap<>();
}
Poly resPoly = new Poly(preMonoMap);
return resPoly;
}
...
}关于化简顺序,我没有什么特别的想法, 采用的顺序化简的方法,把可能比较常见的方法放在前面先做,比较复杂的公式放在后面做。
递推函数和自定义函数的处理
如迭代设计中第二次作业所写的,我是将递推函数和自定义函数放在一起处理,我们可以先考虑特殊情况:自定义函数/递推函数定义的处理。
我的处理流程是:
- 读取输入流,使用正则表达式匹配,获得形参的类型和顺序、表达式的形式,确定映射关系,并且存储到静态类
Definer类内。 - 读取最后的表达式后,读取到函数调用后使用
parseExpr()读取实参的形式,调用Definer类,用replaceAll()方法进行替换,将形参替换为实参。 - 将替换后的字符串调用
Processor, lexer, parser类,把字符串处理为Expr类进行返回。
如果是 n > 1 的递推函数,我选择的方法还是同上,如果此时替换后的字符串内包含规模更小的递推函数,我的 parseExpr() 方法会如此递归解析递推函数,最终返回不含函数调用的 Expr 返回。
如果想要追求性能,我们可以选择增加缓存表,预处理 n > 1 的递推表达式并保存在一张表中,每次调用的时候直接从表里调用相应的式子即可,就不需要像我这样每次解析递推函数时递归调用解析函数。
如果采用字符替换的方式处理,我们需要注意一些细节:
- 在替换进去的实参两边我们需要增加括号,否则我们我们的替换可能会改变运算顺序。
- 建议先将原来的形参先替换成两个不是文法关键字的字符串,最后再将该字符串替换为实参。否则顺序替换
f(y,x)的表达式时可能会将先前替换进的实参替换为第二个实参。
碎碎念
- 如果需要解决程序ctle问题,我们可以使用IDEA自带的’Intellij Profiler’ 分析。
Bug-Hack;强测-互测
我的Bug,出现的原因与分析
我的程序在Hw1和Hw3比较顺利,中测和强测没有出现正确性问题,互测没有被成功hack。
但是在Hw2中,我的程序出现了一个逻辑性问题。
Hw2中在调用 sinFactor.toPoly() / cosFactor.toPoly() 方法的时候忘记特判 三角函数指数为0 的情况。正确想法之一是把指数为0的优先级设置的比三角函数内部表达式为0的情况高。当三角函数指数为0时,我直接按照平常的方法构造了Mono,加上我在toString()方法并没有输出指数为0的项的功能。二者一叠加导致我的程序出了正确性问题。我在三角函数转为Mono之前特殊判断指数是否为0,如果为0则调用常数构建Mono的方法返回常数1。
(有点犹豫是否应该放在这里) 没得到的强测性能分
😎“在6系,你不卷有的是人卷”
Hw1强测满分,需要注意细节。
Hw2由于正确性有错,没能看到自己的程序在错误的强测点所能得到的性能分。
对比Hw2没拿到性能分的强测点,我认为我还需要以下优化:
- 三角函数和角公式$c(sin(x)cos(y) \pm sin(y)cos(x))=csin((x \pm y))
c(cos(x)cos(y) \pm sin(x)sin(y))=ccos((x \mp y))$
😭Hw3我把Hw2漏掉的优化补上了,但是还是喜提三个点85,一个点99.2038,对比我强测的标准输出,还能化简的地方可能在:
有条件(?)的余弦函数二倍角化简。个人感觉余弦函数的二倍角化简判断的情况还是比较复杂的,一不小心就会把结果变长,需要考虑数字长度的问题。这里还有两种可以继续化简的思路。其一是系数余弦函数系数:常数项=2:1,例 $c(2cos^2(x)-1)=ccos((2x))
acos((2x))+bcos^2(x)+c=acos((2x))+(b/2)(2cos^2(x)-1)+(c-b/2)=(a+b/2)cos((2*x))+(c-b/2)$ 先前的Hw2正弦函数二倍角化简条件太强了,没做到$2sin(x)cos^3(x)+sin((2x))sin^2(x)=sin((2*x))$
四倍角$(c2)(sin^4(x)+cos^4(x))=c(2-sin^2((2x)))
c(cos^4(x)-sin^4(x))=ccos((2*x))$ 六倍角$(c8)(sin^6(x)+cos^6(x))=c(3cos((4*x))+5)$
优化顺序的问题,我的有个输出是类似以下的形式(x,y都是表达式,因此长度变化不一定一致)$c(2sin^2(x)cos(y)-sin((2x))cos(y)-2sin((y-x)))$
应该能继续化简为$c(2sin(x)sin((x-y))+2sin((x-y)))$
关于99.2038,以下是我化简后的结果,如果应用余弦函数二倍角,可以再缩短一个字符的长度
407*sin((1560*x\^3*sin(x\^4)*cos(5)))+280*cos((780*x\^3*sin(x\^4)*cos(5)))^2-3500
感觉Hw3想要性能分全部拿满还是十分困难的,不仅把自己的程序写对,还要看强测数据的情况和运气(?)。不过,只要卷赢身边的人,成为最短就可以了👿。
互测中遇到的Bug及构造数据点的思路
我采用的Hack策略主要是根据评测机随机生成数据,走量,进行对拍,辅以人工构造特殊样例。判断结果是否等价,我基本是根据Python的sympy库的函数进行比对,少部分情况会在比对后对结果进行人工/程序复查。
虽然我没有怎么对其他人的程序进行代码审查,没什么经验。但是我觉得,钻研别人的代码是很难理解的比开发者还深的。如果给我时间察看别人代码的话,我可能会着重抓住易错部分的方法和代码进行查看。
这里建议有时间的话可以去翻翻其他星星的代码进行Hack,特别是三角函数化简部分的代码。我这里有遇到其他人过
U1主要蹭上届学长和室友改的评测机。这里还是介绍一下自己构造极端数据的思想法以及从同房间和微信群同学那边学来的思路。
想要造极端数据,思路主要还是根据作业所新增的要求进行构造样例,同时也要兼顾指导书的代价计算公式和代价上限。
造特殊0
0比较特殊,指导书特别强调
Hw1,可以造各种0的0次方,比如
到了Hw2,多了三角函数,可以测
多层嵌套
多层嵌套的tle、ctle和mle问题因程序而异。我怀疑是程序在处理某个部分的时候调用太多次toString()方法,造成大量时间和空间开销。
三角函数嵌套
根据指导书的代价计算公式,在因子外面套一层三角函数,代价仅增加1,但是我们的程序处理时可能要多往下调用一层。
在Hw3,我们有了自定义函数,可以很快速的调用自定义函数来构建多层三角函数嵌套的样例。如(以下样例来自cwz同学):
有些同学sin和cos跑的速度还不一样,可以都试试。
在Hw2,我们只有递推函数,但是递推函数递推式中隐含着自定义函数调用,因此,我构造了以下样例,并hack到了房间中的部分同学:
$f\{n\}(x)=1f\{n-1\}(sin(sin(sin(x))))+0f\{n-2\}(x)$
虽然这个数据躲过了评测机和第一次的数据检查,但我后面计算cost的时候感觉这个式子并不符合互测的要求。后面我根据代价公式简化的式子如下:
$f\{n\}(x)=1f\{n-1\}(sin(sin(sin(x))))+0f\{n-2\}(x)$
表达式嵌套
在Hw2互测结束后,我在同房间同学提交的样例中看到一个奇妙的样例(以下样例来自zwk同学):
$f\{n\}(y,x)=1f\{n-1\}(x,y)+1f\{n-2\}(x,((((((y)))))))$
输出格式
指导书对输出格式有明确的要求。Hw2新增三角函数后,指导书又提出了新的概念,其中有些细节如果不注意的话容易出现错误。
这部分Bug建议是查看房间其他同学的输出部分的代码进行hack。
Hw2中,我hack到其他人三角函数内括号数量出现问题:
符号处理
符号处理部分涉及预处理以及程序逻辑两部分,两个部分可以互补,共同完成符号的处理。
Hw2中,部分同学不能很好的处理递推表达式中连续出现的四个符号,样例如:
$f\{n\}(y,x)=1f\{n-1\}(x,y)+1f\{n-2\}(x,y)+—-1$
自定义函数与递推函数的形参替换
在解析函数调用、形参与实参之间的调用时,可能会出现错误的替换(如把替换进去的实参当成形参进行二次替换),运算顺序改变(如替换时没加括号)等问题。
我尝试构造了这部分的样例,但是发现效果并不理想,大家的程序都很正确。这一部分还是建议查看具体的实现,思考过后再进行针对性的hack。
但是部分同学处理递推表达式的效率可能不高,可以考虑构造一些比较复杂度较低,但是字符串替换可能出问题的数据。例如(来源群友rqh):
$f\{n\}(x, y) = 1f\{n-1\}(x, y)+1f\{n-2\}(y, x)$
三角函数化简
三角函数化简是Unit1难啃的一个大头,也是一个容易出错的点。这部分Bug主要出现在逻辑上,具体问题因程序而异。
这里建议稍微改改评测机,专门输出带各种三角函数样例,这样对其他人三角函数化简正确性的测试会比较高效。
心得体会
😭有过苦思不得解的苦恼,也有过看着自己的代码运行起来的喜悦。痛,并快乐着。
由于OO第一单元是迭代作业,所以我在编写Hw1作业前花了很多时间琢磨程序架构,看了很多个学长学姐的代码。自己也是比较担心自己的架构不好,把自己的后路堵死,导致后面拓展和重构的时候工作量大。但是后面荣老师在课上和我们说重构是长线迭代过程中不可避免的。不重构的架构不一定是好架构,但是重构的目标就是更好的架构。
本次OO的代码量是我到目前为止最大的一次,在本次“递归下降”的迭代作业中,我也是感受到了面向对象的特殊魅力。在构思递归下降的过程中,我需要把握的是如何建立层次关系以及如何设计对象的分工协作。至于具体实现的过程中,我调用其他对象的方法,我可能只是将方法抽象为一个接口或者是一个功能,忽略了方法中具体的实现过程。这种分装的思想使得自己写代码的过程更加流畅,在Debug过程中也可以更好地定位Bug的位置。
关于代码风格。曾经我在看别人代码的时候就感叹过“哇,这个人注释写的好详细”。从阅读者的角度来看,代码风格是一个非常影响阅读体验和阅读效率的一个因素。良好的代码风格不仅能使编写者和阅读者的体验上升,还能减少Bug的发生。
感谢在研讨课和讨论区分享思路和架构的同学们。感谢助教和课程组。
未来方向
- 希望互测返回的信息可以更多一点,如果互测提交的数据点没有通过,希望能提示是cost的问题、答案的问题还是样例格式的问题,这样也可以减轻同学们互测的压力。同时希望能在互测期间增加提交的历史记录,有的时候真的是交了数据之后忘记记录数据了,导致自己不能很好地把握自己hack到的非同质的Bug数,也会减少非恶意提交的次数。
- 希望对于cost代价的说明能够具体一点。能够出一些构造的样例和样例对应的cost代价,帮助我们同学更好地理解如何计算cost。
- 希望能稍微优化一下难度曲线。第一次由于有实验课及先导课的思路及代码,如果直接参考借鉴的话完成作业的速度和难度应该是不大的。同时第三次作业由于架构已经比较完善,同时也有实验课代码的帮忙,新增的功能也能很好地加入架构中,因此第三次作业也比较顺利。第二次作业需要新增三角函数,还需要对三角函数进行化简,感觉工作量还是挺大的。如果以后还需要考察三角函数,也许可以将三角函数因子加入第一次作业,但是可以像第二次实验一样,对三角函数因子内部表达式来一些限制,同时保证强测数据没有三角函数化简。
- 要不要再增加指数函数😃?把三角函数因子的难度分一部分到指数函数以及指数函数和其他函数耦合的情况下。
后记
这是笔者第一篇正式的博文,笔者自知自身写文章的笔力不行。这篇文章也是拖到Unit2电梯博客周才拖出来,此时笔者已经失去了对OO课程的热情。对之前结构遗落下的内容也只是草草填充了事。请原谅我可能有讲述不清楚的地方。
如前言所说,如果这篇文章能对读者有所帮助,我将感到十分荣幸和喜悦。

